|
|





ORGANIZING KDD 2024 IN BARCELONATogether with Ricardo Baeza-Yates I'm General Chair of ACM SIGKDD 2024, the premier international conference in the Data Science area, to be held in Barcelona, 25-29 of August. 
BEST AI-TRACK PAPER AWARD AT EAAMO 2023Our paper Setting the Right Expectations: Algorithmic Recourse Over Time has received the best AI-track paper award at the 3rd ACM Conference on Equity and Access in Algorithms, Mechanisms, and Optimization (EAAMO'23). In this collaboration with Joao Fonseca, Andrew Bell, Carlo Abrate, and Julia Stoyanovich, we propose an agent-based simulation framework for studying the effects of time and a continuously changing environment on algorithmic recourse, i.e., the principle wherein individuals, who received a negative outcome by an algorithmic system, should also get a counterfactual actionable explanation, so to be able to take action and improve their chances of a positive outcome in future attempts. 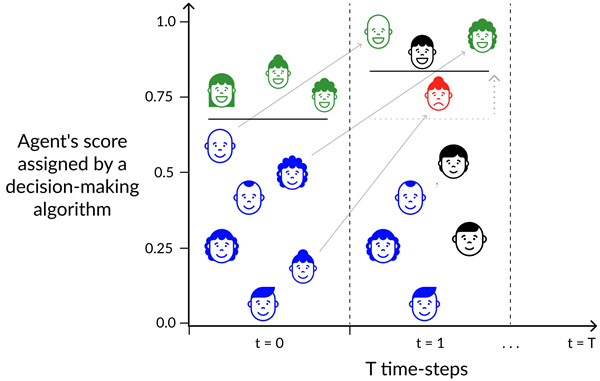
CASCADE-BASED ECHO CHAMBER DETECTIONThe echo chamber effect in social media refers to groups of users that, by being exposed solely to like-minded individuals, tend to reinforce each others pre-existing opinions. This effect has been put under scrutiny as a possible culprit of increased polarization and radicalization. In this new CIKM 2022 paper, we propose to discover echo chambers in social media by looking at how information propagates. In particular, we propose a probabilistic generative model that explains social media footprints (social network structure and propagations of information) through a set of latent communities, characterized by a degree of echo-chamber behavior and by an opinion polarity. Specifically, echo chambers are modeled as communities that are permeable to pieces of information with similar ideological polarity, and impermeable to information of opposed leaning: this allows discriminating echo chambers from communities that lack a clear ideological alignment. 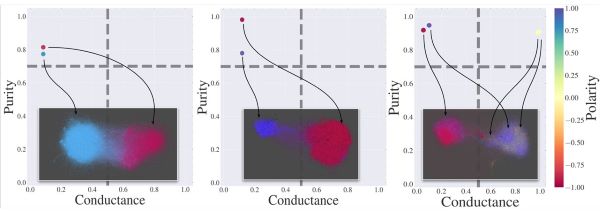
BEST PAPER AWARD AT THE WEB CONF (WWW'22)Great news! Our paper Rewiring what-to-watch-next Recommendations to Reduce Radicalization Pathways got the Best Paper Award at The Web conf (WWW 2022). The motivation at this basis of this work is given by recent studies that have raised concerns about the role played by What-to-watch-next (W2W) recommender systems driving users towards radicalized contents, eventually building radicalization pathways (a user can be driven towards radicalized content even when this wasn't her initial intent). We study the problem of reducing the prevalence of radicalization pathways in W2W recommender systems, while maintaining the relevance of the output, via edge rewiring. Joint work with Francesco Fabbri, Yanhao Wang, Carlos Castillo, and Michael Mathioudakis. 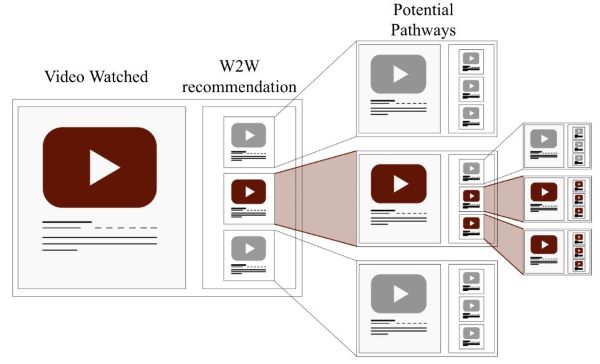
NEW BOOK ON CORRELATION CLUSTERING
Correlation clustering is perhaps the most natural formulation of clustering: as it just needs a definition of similarity, its broad generality makes it applicable to a wide range of problems in different contexts, and, particularly, makes it naturally suitable to clustering structured objects for which feature vectors can be difficult to obtain. Despite its simplicity, generality, and wide applicability, correlation clustering has so far received much more attention from an algorithmic-theory perspective than from the data-mining community. The goal of this book is to show how correlation clustering can be a powerful addition to the toolkit of a data-mining researcher and practitioner, and to encourage further research in the area. COUNTERFACTUAL GRAPHSTraining graph classifiers able to distinguish between healthy brains and dysfunctional ones, can help identifying substructures associated to specific cognitive phenotypes. However, the mere predictive power of the graph classifier is of limited interest to the neuroscientists, which have plenty of tools for the diagnosis of specific mental disorders. What matters is the interpretation of the model, as it can provide novel insights and new hypotheses. In this new KDD 2021 paper we propose counterfactual graphs as a way to produce local post-hoc explanations of any black-box graph classifier. Given a graph and a black-box, a counterfactual is a graph which, while having high structural similarity with the original graph, is classified by the black-box in a different class. 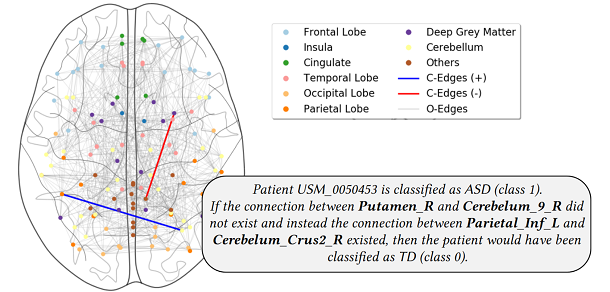
An example of counterfactual graph for a patient from the ABIDE dataset. The patient is classified by a black-box in class ASD (Autism Spectrum Disorder), but with just two edge changes could have been classified as TD (Typically Developed). In gray the edges of the original graph, in red the edge to be removed and in blue the one to be added, so to form the counterfactual graph. In the box, the counterfactual expressed in natural language. Our empirical comparison on different brain network datasets and with different black-boxes show that our proposed search methods can produce good quality counterfactual graphs. Our experiments against a white-box classifier with known optimal counterfactual show that our methods can produce counterfactuals very close to the optimal one. We finally show how counterfactual graphs can be used as ba- sic building blocks to produce LIME-like (SHAP-like) local explanations, as well as global explanations correctly capturing the behaviour of different black- box classifiers and which are meaningful from the neuro-science standpoint. 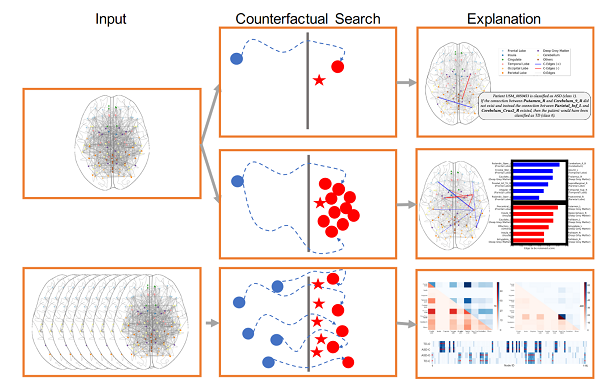
Schematization of the three different types of explanations we can produce by means of graph counterfactuals: Contrastive case-based explanations against counterfactuals (first row), LIME-like (SHAP-like) local explanations (second row), and global explanations (third row). RANDOMIZATION FOR FAIRNESS IN RANKINGIn our new KDD 2021 paper, together with David Garcia-Soriano, we study a novel problem of fairness in ranking aimed at minimizing the amount of individual unfairness introduced when enforcing group-fairness constraints. In fact, while much of the literature for ranking attempts to maximize global utility, global quality metrics generally fail to adequately capture the treatment of individuals. Thus, differently from the literature which tries to maximize the global utility, we adopt Rawlss theory of justice, which advocates arranging social and financial inequalities to the benefit of the worst-off. In order to guarantee the maximum possible value is brought to each individual, in this paper we embrace randomization and produce a probability distribution over possible valid rankings. Our proposal is rooted in the distributional maxmin fairness theory. We devise an exact polynomial-time algorithm to find maxmin-fair distributions of general search problems (including, but not limited to, ranking), and show that our algorithm can produce rankings which, while satisfying the given group-fairness constraints, ensure that the maximum possible value is brought to individuals. To the best of our knowledge, this is the first work studying the problem of minimizing the amount of individual unfairness introduced when enforcing group-fairness constraints in ranking. A major contribution is showing how randomization can be a key tool in reconciling individual and group fairness: we believe that this might hold for other problems, besides ranking CONTRAST SUBGRAPHS FOR BRAIN NETWORKSAn important problem in neuroscience is the identification of connection patterns that might be associated to specific cognitive phenotypes or mental dysfunctions. Given fMRI scans of patients affected by a mental disorder and scans of healthy individuals, the goal is to discover patterns in the corresponding connectomes that explain differences in the brain mechanism of the two groups. Identifying such patterns might provide important insight of the disorder and hint strategies to improve the condition of patients. For this task we propose a simple and elegant, yet effective model, based on extracting contrast subgraph, i.e., a set of vertices whose induced subgraph is dense in the graphs of class A and sparse in the graphs of class B. Our model is extremely simple, it has only one parameter (governing the complexity of the model), it has great accuracy and has excellent interpretability. 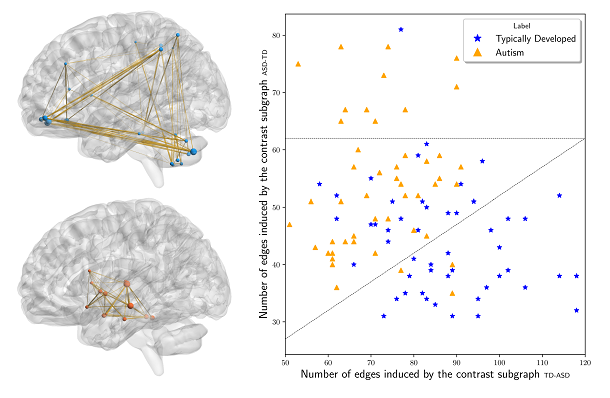
Example of real-world contrast subgraphs extracted from a brain-network dataset consisting of 49 children affected by Autism Spectrum Disorder (class ASD) and 52 Typically Developed (class TD) children. Top-left: the contrast subgraph TD-ASD. Bottom-left: the contrast subgraph ASD-TD. On the right, scatter plot showing for each individual the number of edges present in the subgraph induced by the contrast subgraph TD-ASD (x-axis) and by the contrast subgraph ASD-TD (y-axis). See the paper for more details on the method and the data. DISCOVERING POLARIZED COMMUNITIESGiven a network whose links have annotations to indicate whether each interaction is friendly (positive link) or antagonistic (negative link), we study the problem of finding two communities (subsets of the network vertices) where within communities there are mostly positive edges while across communities there are mostly negative edges. In our new CIKM 2019 paper we formulate this novel problem as a discrete eigenvector problem, which we show to be NP-hard and develop two intuitive spectral algorithms. Joint work with Edoardo Galimberti, Aris Gionis, Bruno Ordozgoiti, and Giancarlo Ruffo. 
An example of two polarized communities in the Congress network. Solid edges are positive, while dashed edges are negative. DISTANCE-GENERALIZED CORE DECOMPOSITIONThe k-core of a graph is defined as the maximal subgraph in which every vertex is connected to at least k other vertices within that subgraph. In this new SIGMOD 2019 paper we introduce a distance-based generalization of the notion of k-core, which we refer to as the (k,h)-core, i.e., the maximal subgraph in which every vertex has at least k other vertices at distance =h within that subgraph. We study the properties of the (k,h)-core showing that it preserves many of the nice features of the classic core decomposition (e.g., its connection with the notion of distance-generalized chromatic number) and it preserves its usefulness to speed-up or approximate distance-generalized notions of dense structures, such as h-club or (distance-generalized) densest subgraph. 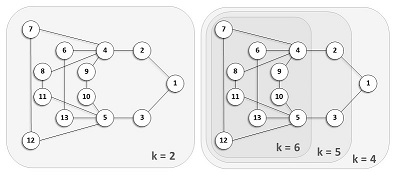
On the left-hand side, the (k,1)-core-decomposition of an example graph (i.e., the classic core de-composition). On the right-hand side, the (k,2)-core-decomposition of the same graph (i.e., distance-generalize core decomposition for a distance threshold h=2). Computing the distance-generalized core decomposition over large networks is intrinsically complex. However, by exploiting clever upper and lower bounds we can partition the computation in a set of totally independent subcomputations, opening the door to top-down exploration and to multithreading, and thus achieving an efficient algorithm. Our experimental assessment confirms the efficiency of our algorithm and the usefulness of distance-based core decomposition in several applications. This is a joint work with Arijit Khan and Lorenzo Severini. SIMPSON'S PARADOX AND SOCIAL INFLUENCEIn 1976, Martin Gardner wrote a Scientific American column with an intriguing title: On the fabric of inductive logic, and some probability paradoxes, discussing E.H. Simpsons reversal paradox, where for example, it is possible that data will confirm each of two hypotheses but disconfirm the two taken together. For instance, for patients with small kidney stones the data confirms that treatment A is better than B; likewise, for patients with large kidney stones the data confirms the same hypothesis. But paradoxically, when one combines the data, it disconfirms the hypothesis, showing the treatment B to be superior of the two! So a reliable causality analysis requires the data to be properly stratified. This is one of several challenges that we deal with in this new CIKM 2018 paper, in which we adopt a principled causal approach, rooted in probabilistic causal theory, to the analysis of social influence from information-propagation data. Our goal is to separate, in a database of information propagation traces, the genuine causal processes from temporal correlation, homophily and other spurious causes. 
Our approach develops around two phases. In the first step, in order to avoid the pitfalls of misinterpreting causation when the data spans a mixture of several subtypes (i.e., the Simpsons paradox), we partition the set of propagation traces in groups, in such a way that each group is as less contradictory as possible in terms of the hierarchical structure of information propagation. For this goal we borrow from the literature the notion of agony and define the Agony-bounded Partitioning problem, which we prove being hard, and for which we develop two efficient algorithms with approximation guarantees. In the second step, for each group from the first phase, we apply a constrained MLE approach to ultimately learn a minimal causal topology. This is a joint work with Francesco Gullo, Bud Mishra, and Daniele Ramazzotti. "RELAXED" COMMUNITY SEARCHFinding subgraphs connecting a given set of vertices of interest is a fundamental graph mining primitive which has received a great deal of attention, and has been studied under different names, e.g., community search, seed set expansion, connectivity subgraphs, etc. While optimizing for different objective functions, the bulk of this literature shares a common aspect: the solution must be a connected subgraph of the input graph containing the set of query vertices. 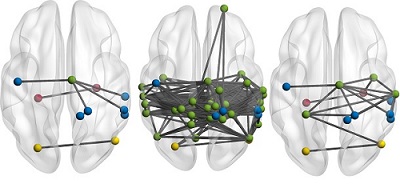
Comparison of different methods on a cortical connectivity network. Query vertices are colored w.r.t. their known functionalities: memory and motor function (blue vertices), emotions (yellow vertices), visual processing (red vertices). The green vertices are the ones added to produce the solution. The left-most solution is the Minimum Inefficiency Subgraph, the central one is the Center-piece Subgraph, the right-most is the Minimum Wiener Connector. The requirement of connectedness is a strongly restrictive one. Consider, for example, a biologist inspecting a set of proteins that she suspects could be cooperating in some biomedical setting. It may very well be the case that one of the proteins is not related to the others: in this case, forcing the sought subgraph to connect them all might produce poor quality solutions, while at the same time hiding an otherwise good solution. By relaxing the connectedness condition, the outlier protein can be kept disconnected, thus returning a much better solution to the biologist. In this new CIKM 2017 paper, we study "relaxed" community search as the problem of finding the subgraph containing the query vertices and minimizing a new measure that we call network inefficiency. 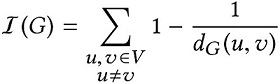
The inefficiency of a subgraph is the sum over all the pairs of vertices of the subgraph of 1 minus the reciprocal of their shortest-past distance. The Minimum Inefficiency Subgraph problem is NP-hard, and we prove that it remains hard even if we constrain the input graph to have a diameter of at most 3. We devise an effcient algorithm that is based on first building a complete connector for the query vertices and then relaxing the connectedness requirement by greedily removing non-query vertices. Our experiments show that in 99% of problem settings, our greedy relaxing algorithm produces solutions no worse than those produced by an exhaustive search, while at the same time being orders of magnitude more efficient. We show interesting case studies in a variety of application domains (such as human brain, cancer, food networks, and social networks), confirming the quality of our proposal. If you're curious, check the paper.DATA TRANSPARENCY LAB (DTL) GRANTThe Data Transparency Lab has awarded our project "FA*IR: A tool for fair rankings in search" one of their grants for the year 2017. The grant will enable the development of an open source API implementing fair ranking methods within a widely-used search engine (Apache SOLR).The DTL grant was awarded to Meike Zehlike (Technische Universität Berlin), Francesco Bonchi (ISI Foundation and Eurecat), Carlos Castillo (Eurecat), Sara Haijan (Eurecat), and Odej Kao (Technische Universität Berlin). Together with Ricardo Baeza-Yates (NTENT) and Mohammed Megahed (Technische Universität Berlin), we have been doing joint research on fair top-k ranking. Some of our results can be found on arXiv pre-print 1706.06368. More details: DTL Grantees 2017 announced. PHD IN DATA SCIENCEUniversity of Bologna is launching the first PhD program in Data Science in Italy and I'm honored to be in its Academic Board. If you are considering getting a PhD under my supervision apply by May 29th: there are 12 fully funded positions (each position lasting for 4 years). See full details here. SECURE MULTILAYER CENTRALITY COMPUTATIONConsider a set of proprietary social networks owned by different, mutually non-trusting, parties: how can these parties jointly compute a centrality score for each of the nodes using all the networks, but without disclosing information about their private graphs? In this new WWW'17 paper we devise secure and scalable multiparty protocols to compute centrality measures. ALGORITHMIC BIAS AND FAIR DATA MININGTogether with Sara Hajian and ChaTo we will be giving a tutorial titled Algorithmic bias: from discrimination discovery to fairness-aware data mining, at the KDD'16 conference in San Francisco, California. More details on the material we will cover are available in the 2-pages outline. CENTRALITY ON BIG GRAPHSTogether with Gianmarco and Matteo we will be giving a tutorial titled Centrality Measures on Big Graphs: Exact, Approximated, and Distributed Algorithms, at the WWW'16 conference in Montreal, Canada. More details on the material we will cover are available in the 4-pages outline. UPDATE: The slides are finally ready and available here. WE'RE HIRINGThe Algorithmic Data Analytics Lab at The ISI Foundation has openings for both Postdoctoral Researchers and Senior Researchers to undertake fundamental research activities related to the development of methods and algorithms for Big Data analysis problems. More information here.ICDM 2016 - BARCELONAI'm glad to announce that I'll be organizer and PC-Chair of The 16th IEEE International Conference on Data Mining (ICDM 2016), which will be held in Barcelona, Spain, December 12-15, 2016. Josep Domingo-Ferrer will be the other PC-Chair, while Ricardo Baeza-Yates and Zhi-Hua Zhou will be the General Chairs. More information soon.NEW JOB(s)!I'm beyond excited to announce that starting from mid September I'll join the ISI Foundation where I'll create and lead the "Algorithmic Data Analytics Lab". At the same time I'll maintain a presence in Barcelona where I'll keep collaborating with the Data Mining team (involving some ex-Yahoos) at the newly founded Technological Center of Catalunya, named Eurecat. The ISI Foundation is a 30 year old research institute that was founded on the principle of challenging Italy to do the best science possible in an environment without constraints. The mission of ISI is defined by a commitment to world-class interdisciplinary research, to knowledge sharing, and to real-world impact on significant challenges of modern society. It is the hub of a vibrant network of scientists from all over the world pursuing basic research in the physical, mathematical, and computer sciences, as well as fundamental and applied challenges in computational thinking and data-driven science. This is one-of-a-kind environment in the European research landscape. It is a fantastic opportunity for me to start a new research team and to conduct high-impact interdisciplinary research. 
The ISI Arc of Science. Today the ISI Foundation is an international organization based in Torino, Italy and with a new office in New York City: I'm looking forward to visit the Big Apple in the coming months and to engage with the local research community. LINK PREDICTION WITH EXPLANATIONSUser recommender systems are a key component in any online social networking platform: they help the users growing their network faster, thus driving engagement and loyalty. In this new KDD paper we study link prediction with explanations for user recommendation in social networks. For this problem we propose WTFW (Who to Follow and Why), a stochastic topic model for link prediction over directed and nodes-attributed graphs. Our model not only predicts links, but for each predicted link it decides whether it is a topical or a social link, and depending on this decision it produces a different type of explanation. 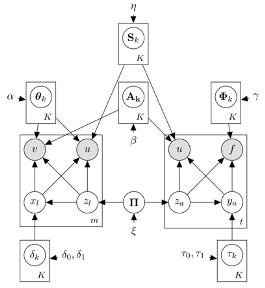
The WTFW model in plate-notation. Enriching recommendations with explanations has the benefit to increase the trust of the user in the recommendation, and thus the likelihood that the recommendation is adopted. While these benefits are well understood in classic collaborative-filtering recommender systems, providing explanations in the context of user recommendation systems is still largely underdeveloped: in fact, in most of the real-world systems, the unique explanations given for user recommendations are of the type you should follow user Z because your contacts X and Y do the same. Instead, our starting observation (and driving motivation) is that a link creation is usually explainable by one of two main reasons: interest identity (topical) or personal relations (social). This observation is rooted in sociology, where it goes under the name common identity and common bond theory. THE PURSUIT OF A GOOD POSSIBLE WORLDAn uncertain graph, i.e., a graph whose edges are associated with a probability of existence, can be seen as a set of 2^|E| possible worlds. Each possible world is a deterministic instantiation of the uncertain graph. In this new SIGMOD paper we study the problem of selecting just one possible world given an uncertain graph. In particular, we want to select a "good" possible world: one that preserves the underlying graph properties. Starting from the observation that the vertex degree is one of the most fundamental properties of the structure of a graph, we conjecture that by preserving the degree of each vertex we capture the essence of the underlying uncertain graph, and thus accurately approximate other properties. Therefore we study the problem of selecting a deterministic instance of the uncertain graph, which minimizes the sume over all vertices of the difference of their expected degree in the uncertain graph, and the degree in the deterministic instance. COMMUNITY DETECTION WITHOUT THE NETWORKWhile the literature on community detection methods is wide, the applications are mainly limited to data analysis for social sciences. This is due to a fundamental observation: the players which would benefit more from knowing the community structure of a social network, e.g., companies advertising or developing web applications, often do not have access to the whole network! It is a matter of fact that the social network platforms are owned by third party such as Facebook or Twitter, which have realized that their proprietary social graph is an asset of inestimable value. Thus they keep it secret, for sake of commercial competitive advantage, as well as due to privacy legislation. In this new ICDM'13 paper we tackle the challenging problem of learning communities when not even the social graph is available. Instead what we have is a database of past propagations. We propose a stochastic framework which assumes that the cascades are governed by un underlying diffusion process over the unobserved social network, and that such diffusion model is based on community-level influence. By fitting the model parameters to the user activity log, we learn the community membership and the level of influence of each user in each community. This allows to identify for each community the key users,, i.e., the leaders, which are most likely to influence the rest of the community to adopt a certain item. Unfortunately the paper has been accepted as a short paper, so only 6 pages. We have much more material to show, especially esperiments on real data. We will soon distribute a longer version of our work. Stay tuned. DENSER THAN THE DENSEST SUBGRAPHMotivated by the fact that the direct optimization of edge density is not meaningful, as even a single edge achieves maximum density, research has focused on optimizing alternative density functions. A very popular among such functions is the average degree, whose maximization leads to the well-known densest-subgraph notion. Despite its name, the densest subgraph often results to be a large graph, with small edge density and large diameter. In this new KDD'13 paper, we define a novel density function, which gives subgraphs of much higher quality than densest subgraphs: the graphs found by our method are compact, dense, and with smaller diameter. The proposed notion of density that we dub optimal quasi-clique, is derived by turning the quasi-clique condition into an objective function: the goal is to maximize the number of edges that are present in the subgraph compared to the number of edges expected under the Erdös-Rényi random-graph model. 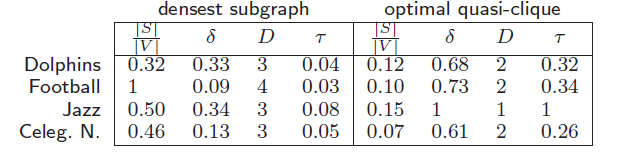
Difference between densest subgraph and optimal quasi-clique on some popular graphs. The four columns report (i) fraction of vertices in the subgraph compared to the whole graph, (ii) edge density, (iii) diameter, and (iv) triangle density. Results on many other popular graphs can be found in the paper. THE BANG FOR THE BUCKIn this new KDD'13 paper we study competitive viral marketing from the host perspective. Competitive viral marketing refers to the case in which two or more players compete with comparable products over the same market. By host we mean the social networking platform owner, which offers viral marketing as a service to its clients. From the hosts perspective, it is important not only to choose the seed nodes to target in the campaigns in such a way to maximize the collective expected number of adoptions across all companies, but also to allocate seeds to companies in a way that guarantees the ''bang for the buck'' for all companies is nearly the same. Intuitively, the bang for the buck for a company is the cost benefit ratio between the expected number of adopters of its product over its number of seeds. For more details, please read the paper. STRIP: STREAM LEARNING OF SOCIAL INFLUENCEIn this new (sexy) KDD'13 paper we introduce STRIP, a suite of streaming methods for computing the strength of social influence along each link of a social network. STRIP allows to compute social influence from the continous stream of actions performed by the users of a social networking platform. Thanks to a wise use of probabilistic approximations, min-wise independent hashing functions, and streaming sliding windows, STRIP can learn influence strength with only one pass over the data and using little memory, thus allowing to scale to big data. CASCADE-BASED COMMUNITY DETECTIONUnderstanding how the adoption of new practices, ideas, beliefs, technologies and products can spread trough a population driven by social influuence, is a central issue for the whole of social sciences. Taking into account the modular structure of the underlying social network provides further important insight in the phenomena known as social contagion or information cascades. In particular, individuals tend to adopt the behavior of their social peers, so that cascades happen first locally, within close-knit communities, and become global viral phenomena only when they are able cross the boundaries of these densely connected clusters of people. Therefore, the study of social contagion is intrinsically connected to the problem of understanding the modular structure of networks (known as community detection). 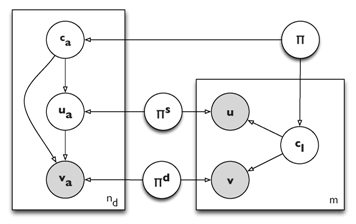
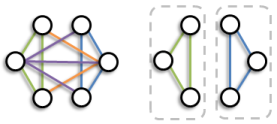
The CCN model in plate-notation. Given a directed social graph and a set of past information cascades observed over the graph, in this new WSDM'13 paper (joint work with Nicola Barbieri and Giuseppe Manco) we study the novel problem of detecting modules of the graph (communities of nodes), that also explain the cascades. Our key observation is that both information propagation and social ties formation in a social network can be explained according to the same latent factor, which ultimately guide a user behavior within the network. Based on this observation, we propose the Community-Cascade Network (CCN) model, a stochastic mixture membership generative model that can fit, at the same time, the social graph and the observed set of cascades. Our model produces overlapping communities and for each node, its level of authority and passive interest in each community it belongs. CHROMATIC CORRELATION CLUSTERING
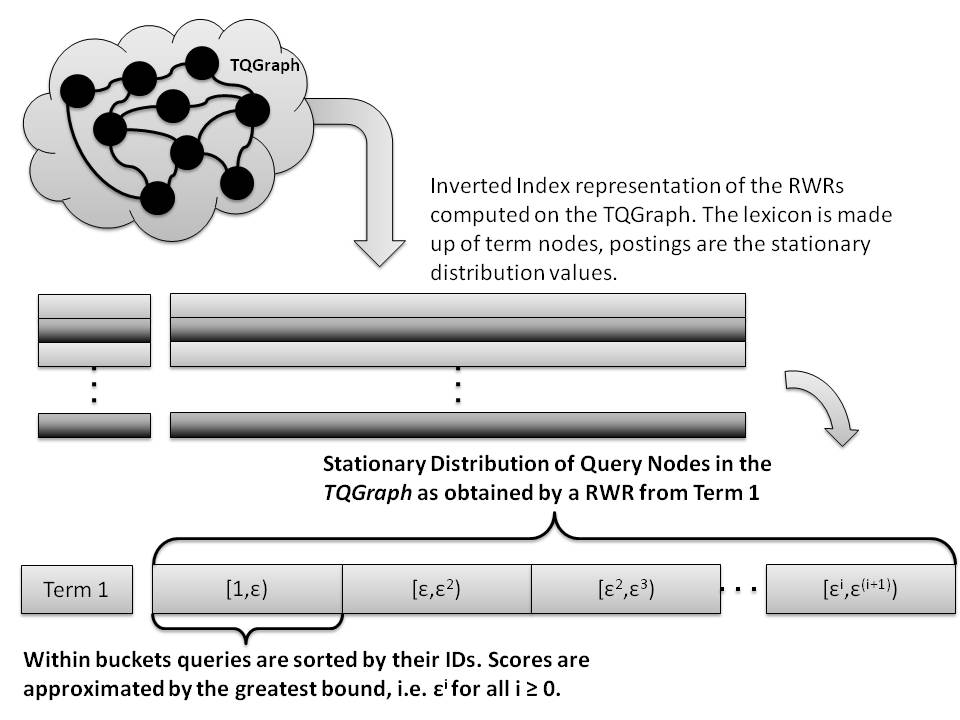
Our problem can be naturally viewed as partitioning the vertices of a graph whose edges are of different types, or as we like to think about them, different colors. The key objective in our framework is to find a partition of the vertices of the graph such that the edges in each cluster have, as much as possible, the same color (an example is in the picture above). The framework has plenty of applications. As an example, biologists study protein-protein interaction networks, where vertices represent proteins and edges represent interactions occurring when two or more proteins bind together to carry out their biological function. Those interactions can be of different types, e.g., physical association, direct interaction, co-localization, etc. In these networks, for instance, a cluster containing mainly edges labeled as co- localization, might represent a protein complex, i.e., a group of proteins that interact with each other at the same time and place, forming a single multi-molecular machine. As a further example, social networks are commonly represented as graphs, where the vertices represent individuals and the edges capture relationships among these individuals. Again, these relationships can be of various types, e.g., colleagues, neighbors, schoolmates, football-mates. Check out our techniques in the paper. QUERY RECOMMENDATIONS IN THE LONG TAILIn a new paper (accepted at SIGIR'12, together with R. Perego, F. Silvestri, R. Venturini, H. Vahabi) we introduce a new method for query recommendation based on the well-known concept of center-piece subgraph, that allows for the time/space efficient generation of suggestions also for rare, i.e., long-tail queries. We shift the focus from the queries to the
terms they contain, thus devising a novel graph-based method
that at once solves the two issues: it produces high-quality
recommendations also for long-tail queries, achieving a coverage of approximately 99% of a real-world search engine
workload, while enjoying high scalability.
The term-centric perspective we take, not only solves the long-tail coverage issue, but it also allows the stationary distributions of such a Markov chain to be precomputed and stored in a compressed and cached index, thus achieving efficiency and scalability. In particular, we introduce a method based on an inverted index compressed by using a lossy compression method able to reduce by an average of 80% the space occupancy of the uncompressed data structures. Furthermore, caching is exploited at the term-level to enable scalable generation of query suggestions. Being term-based, caching is able to attain hit-ratios of approximately 95% with a reasonable footprint (i.e., few gigabytes of main memory). INFLUENCE MAXIMIZATION: a data-based approachWhile most of the literature on Influence Maximization has focused mainly on the social graph structure, in our new paper (accepted for VLDB'12 [bibtex], together with Amit Goyal and Laks V. S. Lakshmanan) we proposed a novel data-based approach, that directly leverages available traces of past propagations.  Our Credit Distribution model estimates influence spread by exploiting historical data, thus avoiding the need for learning influence probabilities, and more importantly, avoiding costly Monte Carlo simulations, the standard way to estimate influence spread. Based on this, we developed an efficient, effective, and scalable algorithm for the Influence Maximization problem. Beyond this main contribution, the paper provides several interesting insights in the Influence Maximization problem. Check it out! MY KEYNOTE TALK AT WI-IAT 2011Please find below the slides I will use in my keynote talk this morning at WI-IAT 2011 in Lyon. The talk is entitled Influence Propagation in Social Networks: a Data Mining Perspective (pdf). If you want the powerpoint, please e-mail me .SPARSIFICATION OF INFLUENCE NETWORKS [June 2011]SPINE (SParsification of Influence NEtworks) is a new algorithm for discoverying the "backbone" of an influence network. Given a social graph and a log of past propagations, we build an instance of the independent-cascade model that describes the propagations. We aim at reducing the complexity of that model, while preserving most of its accuracy in describing the data. The paper will be presented next August at the KDD 2011 conference. #viscous_democracy #castelleres @CACM [June 2011]Our paper Viscous democracy for social networks,
(together with Paolo Boldi, Carlos Castillo and Sebastiano Vigna) has been published in the virtual extension of the June 2011 issue of Communications of ACM. LINK PREDICTION: A RULE-BASED APPROACH [Apr 2011]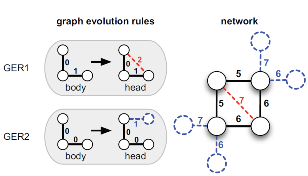 Recently I've seen a nice survey on Link Prediction covering a lot of different approaches, but overlooking our frequent pattern based approach introduced in:
Recently I've seen a nice survey on Link Prediction covering a lot of different approaches, but overlooking our frequent pattern based approach introduced in:
Bringmann et al. Learning and Predicting the Evolution of Social Networks IEEE Intelligent Systems ©IEEE 25(4):26-35 - Jul/Aug 2010. Briefly, in this paper we extend our previous work on Mining Graph Evolution Rules, showing how to use those rules for Link Prediction. Our method is quite different from standard Link Prediction, and leverages the history of the network evolution till now to predict future evolution. Our frequent pattern based approach not only predicts arrival of new edges among pairs of existing nodes, but also allows to predict edges among one existing node and a new node that is not yet part of the graph. NEW BOOK ON PRIVACY AND MINING [Jan 2011]
Check out Elena's interview with the IEEE Computer Society. TAXOMO SOFTWARE RELEASED [Jan 2011]I am glad to announce that today we released the TAXOMO sequence mining software under a BSD license. TAXOMO is a data-mining tool for sequences. It takes as input a set of sequences and a taxonomy, and generates a succinct description of the sequences (specifically, a Markov chain with lumped states). The input sequences may represent any kind of data, e.g.: trajectories on a map, web pages visited by a user, etc. The taxonomy should be defined over the states in the sequences. In the case of a map, for instance, they can be regions and sub-regions for the points in the map. In the case of a web site, they can be categories and sub-categories for the pages. Taxomo was developed at Yahoo! Research Barcelona, and it is described in:Bonchi et al. Taxonomy-driven lumping for sequence mining Data Mining and Knowledge Discovery Journal ©Springer 19(2):227-244 - Oct 2009. For more information and download, see: http://taxomo.sourceforge.net/  Example of application of TAXOMO to a dataset of trajectories. (a) Road network used to generate the trajectories dataset. (b) Markov model of the whole dataset at the leaves level (i.e., the original grid with 1,024 states). (c) Markov model of the whole dataset with 175 states, found by Taxomo. Arc thickness represents the probability of the transition.. ICDM 2010 PANEL [Dec 2010]I was a panelist at ICDM'10. The panel was entitled "Top-10 Data Mining Case Studies". The other panelists were: Ashok Srivasta, Bart Goethals, Rayid Ghani, Christos Faloutsos, Longbing Cao, Osmar Zaiane, Rong Duan, Paul Beinat, and Geoff McLachlan. The panel chairs were Gabor Melli and Xindong Wu.YAHOO! CLUES LAUNCHED [Nov 2010]Yahoo! launched Clues, a service based on science from Yahoo! Research Barcelona. Yahoo! Clues lets you explore how people are using Yahoo! Search. When you enter a word or phrase in the "Search Term" field and click Discover, youll see information about that search terms popularity over time, across demographic groups, and in different locations. You can also enter a second search term in the "Compare With" field. This will show you information on both search terms, side by side.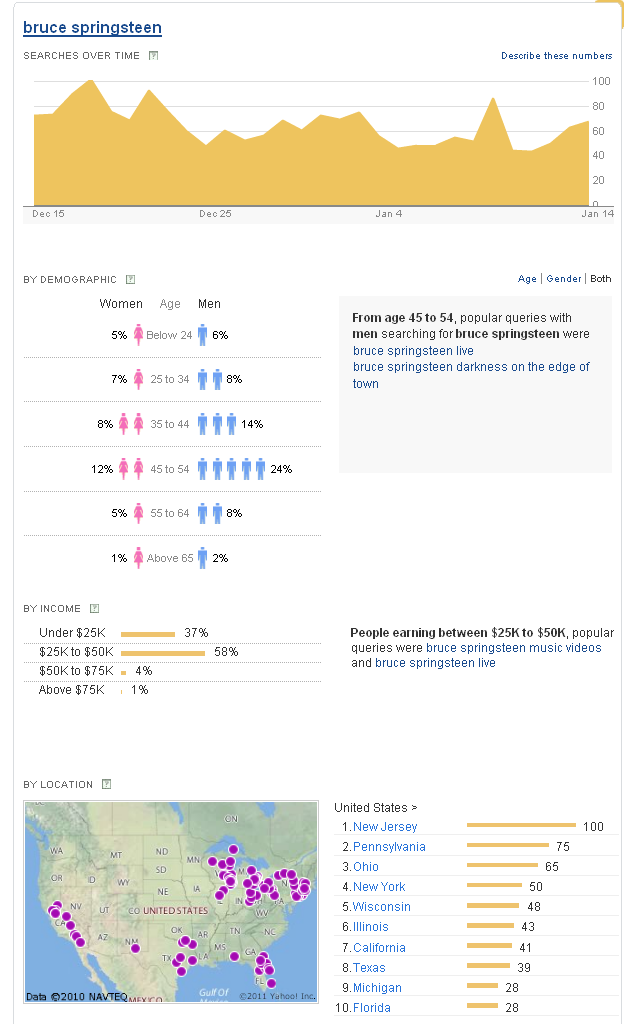
Among other things, it allow users to browse a real query-flow graph:
|
RECENT PUBLICATIONS
|

 In this
In this 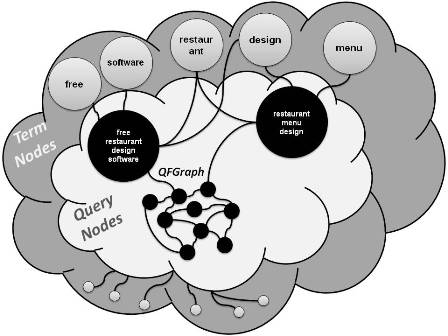 Our method is based on a graph having term nodes, query
nodes, and two kinds of connections: term-query and query-query.
The first connect a term to the queries in which
it is contained, the second connect two query nodes if the
likelihood that a user submits the second query after having
issued the first one is sufficiently high. Such graph induces
a Markov chain on which a generic random walker starts
from the subset of term nodes contained in the incoming
query, moves along query nodes, and restarts (with a given
probability) only from the same initial subset of term nodes.
Computing a recommendation this way corresponds to finding the center-piece subgraph induced by terms contained into
the query.
Our method is based on a graph having term nodes, query
nodes, and two kinds of connections: term-query and query-query.
The first connect a term to the queries in which
it is contained, the second connect two query nodes if the
likelihood that a user submits the second query after having
issued the first one is sufficiently high. Such graph induces
a Markov chain on which a generic random walker starts
from the subset of term nodes contained in the incoming
query, moves along query nodes, and restarts (with a given
probability) only from the same initial subset of term nodes.
Computing a recommendation this way corresponds to finding the center-piece subgraph induced by terms contained into
the query. In this article, we propose a middle-ground between direct democracy (citizens vote on every issue) and representative democracy (citizens elect representatives that decide on their behalf on every issue). Our proposal, a type of delegative democracy, allows them to express their opinion directly or to delegate their power on a proxy.
Proxy delegation can be transitive: a proxy can delegate in another proxy. However, as our vote travels farther away through a delegation chain, we would like to introduce some reluctance in the way the power is transferred to other people we may not know directly. In that sense, we include a dampening factor (like PageRank does) to reduce the amount of power delegated through long chains. Technically, our system of viscous democracy is a system of transitive proxy voting with exponential damping.
In this article, we propose a middle-ground between direct democracy (citizens vote on every issue) and representative democracy (citizens elect representatives that decide on their behalf on every issue). Our proposal, a type of delegative democracy, allows them to express their opinion directly or to delegate their power on a proxy.
Proxy delegation can be transitive: a proxy can delegate in another proxy. However, as our vote travels farther away through a delegation chain, we would like to introduce some reluctance in the way the power is transferred to other people we may not know directly. In that sense, we include a dampening factor (like PageRank does) to reduce the amount of power delegated through long chains. Technically, our system of viscous democracy is a system of transitive proxy voting with exponential damping.
{kind=link}